主要内容有:
- 模型选择、评价指标
- 绘制数据,欠拟合、过拟合曲线及学习曲线
这篇博客的主要来源是吴恩达老师的机器学习第六周的学习课程,还有一些内容参考自黄海广博士的笔记GitHub
我先根据作业完成了matlab代码,并将它用python来实现(博客中无matlab实现)
实现过程中我结合吴恩达老师的上课内容和matlab代码修改了一部分代码(个人认为可以优化的地方)
advice for applying machine learning
deciding what to try next
当我们使用一些新的测试集来测试我们已经训练好的模型时,如果出现较多的误差(分类错误或者 回归问题与正确预计值相去甚远),我们可以尝试:
- 获得更多的训练样本
- 减少/增加特征数量
- 减小/增大$\lambda$ 用来减少/增加正则化程度
- 添加多项式特征
为了让我们知道应该尝试哪一种,我们需要评估机器学习算法性能,进行机器学习诊断(Diagnostic),来提高我们的算法性能
Diagnostic可能需要花费一定的时间,但是这些时间是值得的,可能会起到事半功倍的效果
Evaluating a Hypothesis
如何判断模型是欠拟合还是过拟合呢
在2D的时候 我们可以通过画图来发现我们的hypothesis是否过拟合了,但是在高维数据下,想要通过画出hypothesis来进行观察,就会变得很难甚至是不可能实现。,因此我们需要另一种方法来评估
一般情况下,我们会将数据随机的划分为训练集和测试集,比如70%的数据用来训练,而30%的数据用来测试(来评价我们的模型的generalization ability)
具体地:
我们使用训练集来获得我们的parameters($\theta$),使用测试集来计算test set error
test set error一般是计算代价函数(J),对于逻辑回归(分类)的话,我们可以这样计算:
$J_{test}(\theta) = \frac{1}{m_{test}}\sum_{i=1}^{m_{test}}[-y_{test}^{(i)}log(h_{\theta}(x_{test}^{(i)}))-(1-y_{test}^{(i)})log(1-h_{\theta}(x_{test}^{(i)}))]$
我们还可以这样计算:
$J_{test}(\theta) = \frac{1}{m_{test}}\sum_{i=1}^{m_{test}}err(h_{\theta}(x)^{i},y^{(i)})$
其中$err(h_{\theta}(x),y) = \left\{\begin{matrix}
1 (if… h_{\theta}(x) \geq 0.5, y = 0).. or… (if…h_{\theta}(x) \leq 0.5,y=1)
\\
0 (othersize)
\end{matrix}\right.$
Model Selection and training/validation/test Sets
一般来说,当我们的模型发生过拟合时,我们的training error$J(\theta)$ 通常会比实际的generalization error低很多,因为我们训练的时候,我们的参数(parameters)总是在fit training set
我们应该如何选择我们的模型呢?
如果我们如上文一样,仅仅将数据分为training set和test set
假设我们有多组不同的参数,我们想要从中选出最优的,我们会怎么选择呢?
我们通常会选择test error最小的,作为我们模型的最优parametes
但是,如果我们使用的是test error最小的,那我们如何才能评估我们模型的泛化能力呢?(也就是获得定量的generalization error)
如果我们使用test error作为我们的generalization error会出现这样的问题:
吴恩达老师说:
$min J_{test}(\theta)$ is likely to be an optimistic estimate of generalization error i.e. our extra paramter(d = degree of ploynomial) is fit to the test set
这里d是多项式的次数,比如下面的
- $h_{\theta}(x) = \theta_{0} + \theta_{1}x$
- $h_{\theta}(x) = \theta_{0} + \theta_{1}x + \theta_{2}x^2$
- $h_{\theta}(x) = \theta_{0} + \theta_{1}x + \theta_{2}x^2 + \theta_{3}x^3$
… - $h_{\theta}(x) = \theta_{0} + \theta_{1}x + \theta_{2}x^2 +… \theta_{10}x^{10}$
也就是说 我们的模型实际上也从test set中学习了最优的参数,因此使用test error不能很好的衡量我们的generalization error
所以:
我们会将数据划分为三部分
- training set 如60%
- cross validation set 如20%
- test set 如20%
接下来我们使用training set $J_{train}(\theta)$训练,找出最小的cross validation error $J_{cv}(\theta)$所使用的parameters,然后再用我们的模型来计算test error$J_{test}(\theta)$,用test error来作为评估我们的模型泛化能力的指标
$J_{cv}(\theta)$一般会比$J_{test}(\theta)$小,因为an extra parameter(d) has been fit to the class validation set
而 $J_{test}(\theta)$ 可以用来衡量泛化能力是因为:
the degree of the ploynomial d has not been trained using the test set
感觉翻译起来怪怪的,干脆直接贴英文吧
Diagnosing Bias vs. Variance
下面是High bias和High variance的示例图片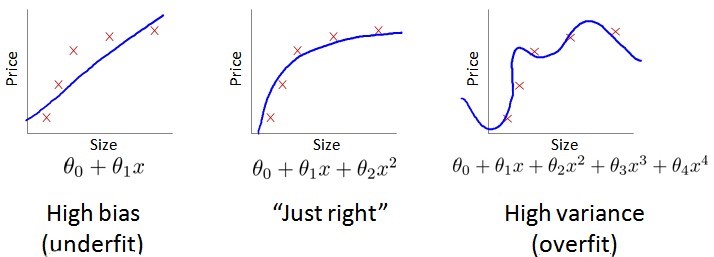
要判断是否发生了过拟合还是欠拟合,更一遍的情况下,我们会使用参数做横坐标,画出误差曲线,比如这里使用d,而下面的练习中会使用$\lambda$来绘制,如下图:
这里面比较重要的是:
- High bias(underfiting): $J_{cv} \approx J_{train} $ ,并且这两个值都较高
- High variance(overfitting): $J_{train}$低 并且 $J_{cv} \gg J_{train}$(两个值相差较大)
Regularization and Bias_Variance
在我们在训练模型的过程中,我们会添加正则化项来防止过拟合。但是$\lambda$的取值也是我们需要考虑的事情(和上面的d一样)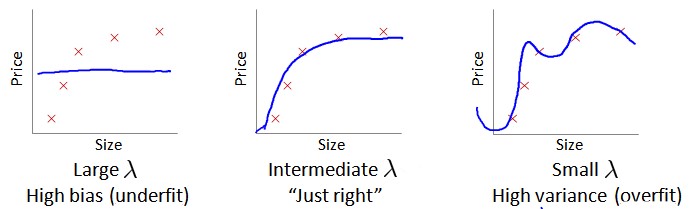
那么我们选择$\lambda$ 的方法如下:
- 创造一个list,里面是$\lambda$的各种取值:如:[0,0.01,0.02,0.04,0.08,0.16,0.32,0.64,1.28,2.56,5.12,10.24]
- 使用不同的$\lambda$来学习$\theta$(还可以选择不同的d来用不同的$\lambda$学习)
- 计算$J_{cv}$,这里的$J_{cv}$是不带正则化项的(或者说$\lambda=0$)
- 找出最小的$J_{cv}$模型M
- 使用M中的params,计算$J_{test}$来评估我们的模型是否具有泛化问题
需要注意的是,我们在计算$J_{cv},J_{train},J_{test}$中都不需要加入正则项,而在我们训练模型时的$J$需要加入正则化项,这样做的原因是为了减少过拟合
下图中: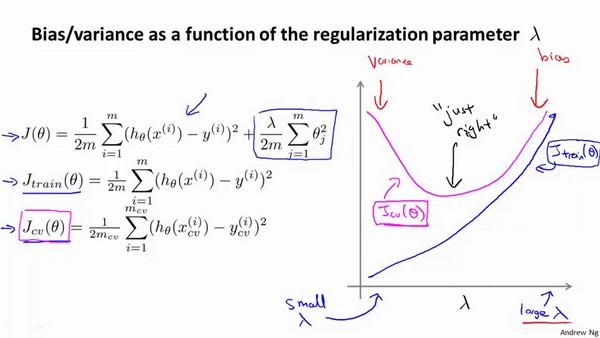
$\lambda$较小时,$J_{train}$较小(overfitting),$J_{cv}$较大
随着$\lambda$增大,$J_{train}$不断增加(under fitting),而$J_{cv}$是先减小后增大
Learning Curves
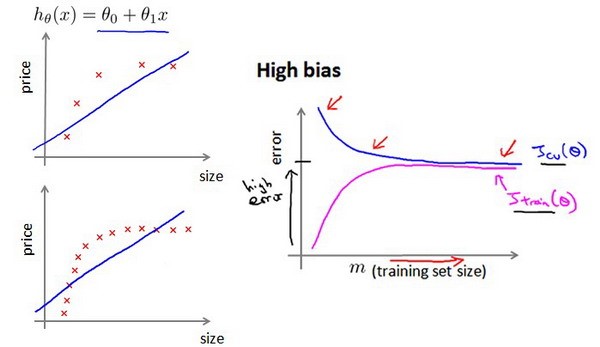
在high bias(underfit)下,添加更多的训练集不一定会起作用
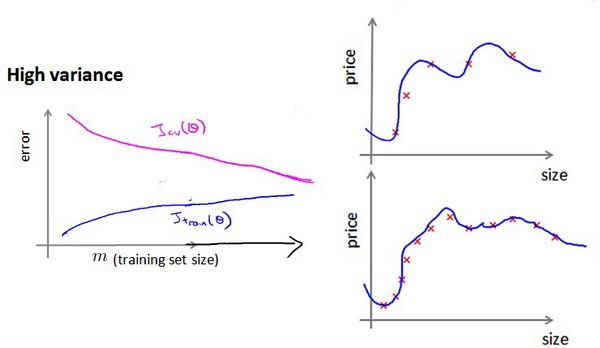
在high variance(overfitting)下,添加更多的训练集可能会是我们的模型表现的更好
Deciding What to Do Next Revisited
- 获得更多的训练样本 — 解决high bias
- 减少/增加特征数量 — 解决high variance/high bias
- 减小/增大$\lambda$ — 解决high bias/high variance
- 添加多项式特征 — 解决high bias
而对于神经网络而言:
- parameters越少(小型网络),越容易欠拟合,但是计算代价小
- parameters越少(大型网络),越容易过拟合,但是计算代价大
代码实现
代码中 导入数据集 计算线性回归的代价函数、梯度 训练线性回归模型在之前的练习中都有写过
下面是完成练习中主要实现的代码:
计算$J_{train},J_{cv}$
1 | def learningCurves(Xtrain,ytrain,Xval,yval,lambdaa): |
还有一个代码是选做的,随机选择样本来绘制学习曲线
计算$J_{randomTrain},J_{randomCv}$
1 | def randomLearningCurves(Xtrain,ytrain,Xval,yval,lambdaa): |
添加多项式特征
这个代码的写法具有学习意义,所以单独摘出来:
1 | def normalizeFeature(df): |
接下来还需要注意的代码,就是画图了
我画出来的图像如下: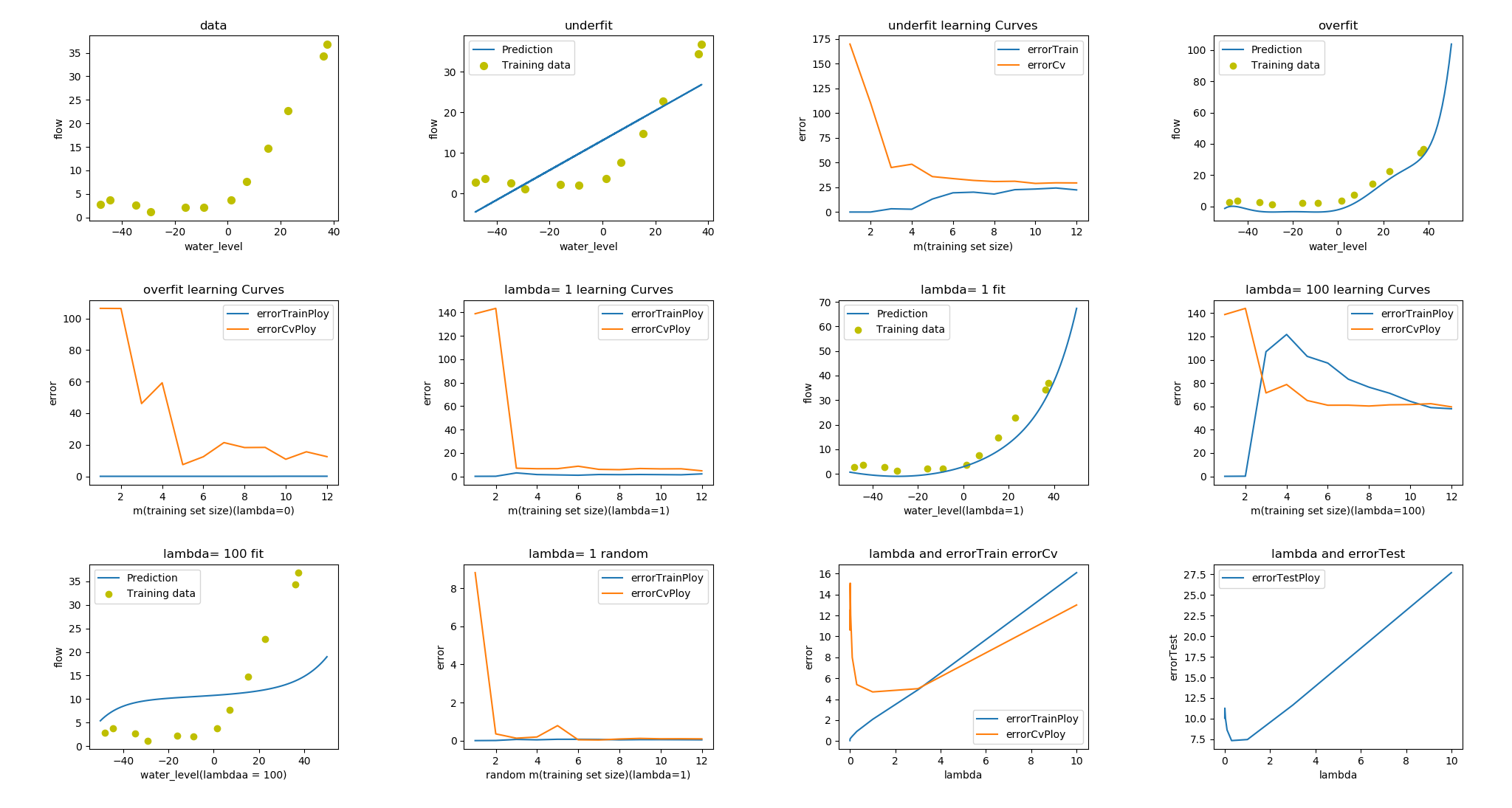
完整代码比较长,我将贴在本文的最后
References
完整代码
1 | import numpy as np |